Gleaner in the Context of Communities Leveraging FAIR Principle
The Community Context
This document provides some context to where GleanerIO can be leveraged by communities who are implementing FAIR principles. These could be communities of practice or groups of domain related facilities.
To provide further context a set of personas can be defined that help set the stage and provide scoping for the various parts of a community and their relations.
Personas
About
To provide better context we can define three personas to better express the roles within a community.

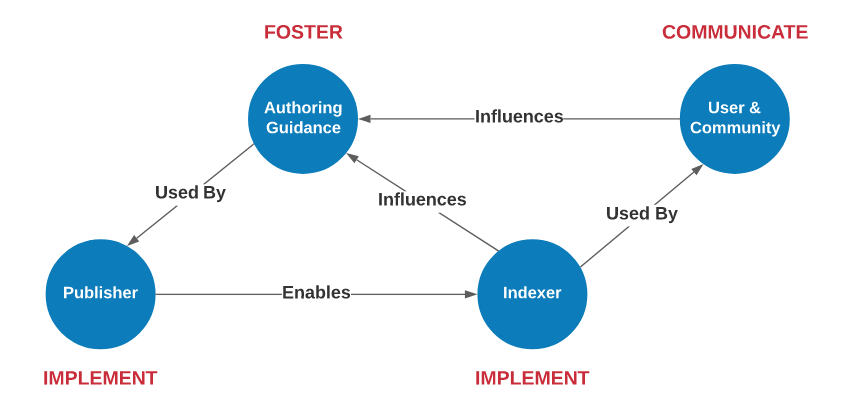
Persona: Publisher
The Publisher is engaged authoring the JSON-LD documents and publishing them to the web. This persona is focused on describing and presenting structured data on the web to aid in the discovery and use the resources they manage. Details on this persona can be found in the Publisher section.
Additionally, this persona would be leveraging this encoding described in the JSON-LD Foundation section and the profiles described in the Thematic Patterns.
Persona: Indexer
The Indexer or Aggregator is a person or organization who is indexing resources on the web using the structured data on the web patterns described in this documentation.
Their goal is to efficiently and efficiently index the resources exposed by the Publisher persona and generate usable indexes. Further, they would work to exposed these indexes in a manner that is usable by the User persona. Details on the approach used by OIH and potential alternatives can be found in the Aggregator section.
Persona: User
The user is the individual or community who wished to leverage the indexes generated as a result of the publishing and aggregation activities. The user may be using the developed knowledge graph or some web interface built on top of the knowledge graph or other index. They may also use query languages like SPARQL or other APIs or even directly work with the underlying data warehouse of collected data graphs.
User tools may be web sites or scientific notebooks. Some examples of these user experiences are described in the User section.
FAIR Implementation Network
We can think of the above personnas and how they might be represented in a FAIR implementation network. The diagram that follow represents some of these relations.
Gleaner
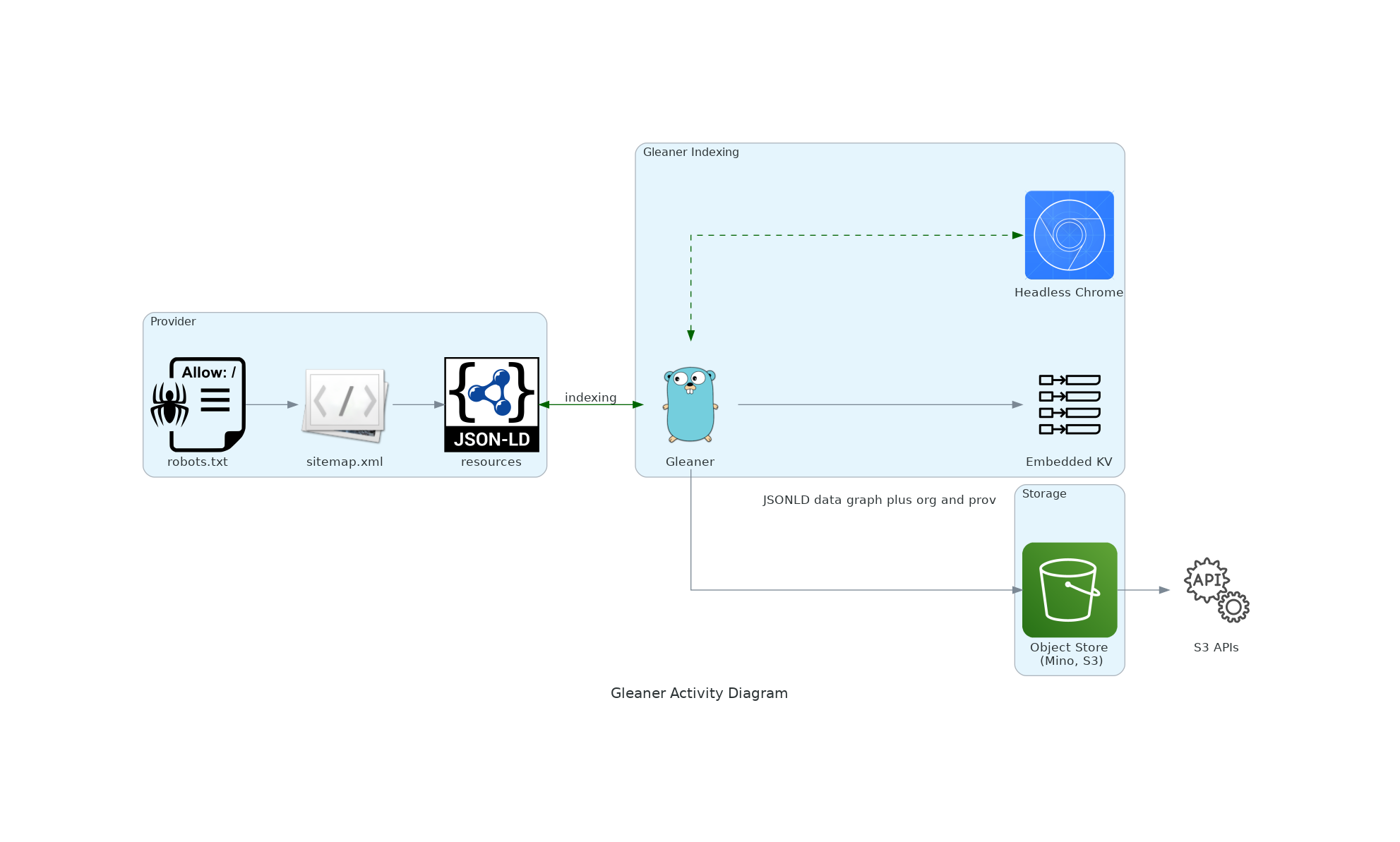
Gleaner is a tool for extracting JSON-LD from web pages. You provide Gleaner a list of sites to index and it will access and retrieve pages based on the sitemap.xml of the domain(s). Gleaner can then check for well formed and valid structure in documents. The product of Gleaner runs can then be used to form Knowledge Graphs, Full-Text Indexes, Semantic Indexes, Spatial Indexes or other products to drive discovery and use.
GleanerIO is the set of reference tools that have been developed to support organizations to harvest and leverage structure data on the web. The tools can be found at: https://github.com/gleanerio and include:
- Gleaner: a structured data harvesting tool
- Nabu: an ETL/ELT tool for loading JSON-LD data graphs into various data systems such as triple-stores, text index, spatial indexes, etc.
- Scheduler: an automated workflow system built on Dagster
- Example Jupyter notebooks
- Example web UIs
- Documentation
Principles over Project
The approach to using structured data on the web can be viewed in the context of Principles over Project. The view that the import aspects are the basic principles and not the implementation or code used to address the goal. Nothing in Gleaner or in an activity implementation using Gleaner is critical. All the components of the approach can be replaced with other approaches, including Gleaner itself which can be replaced with other software packages.
| Principles | Project |
|---|---|
| Structured data on the web | Gleaner harvested data graphs |
| Web architecture | https |
| Semantics / Context | schema.org (Science on Schema) DCAT, GepSPARQL, PROV |
| Open formats | JSON-LD |
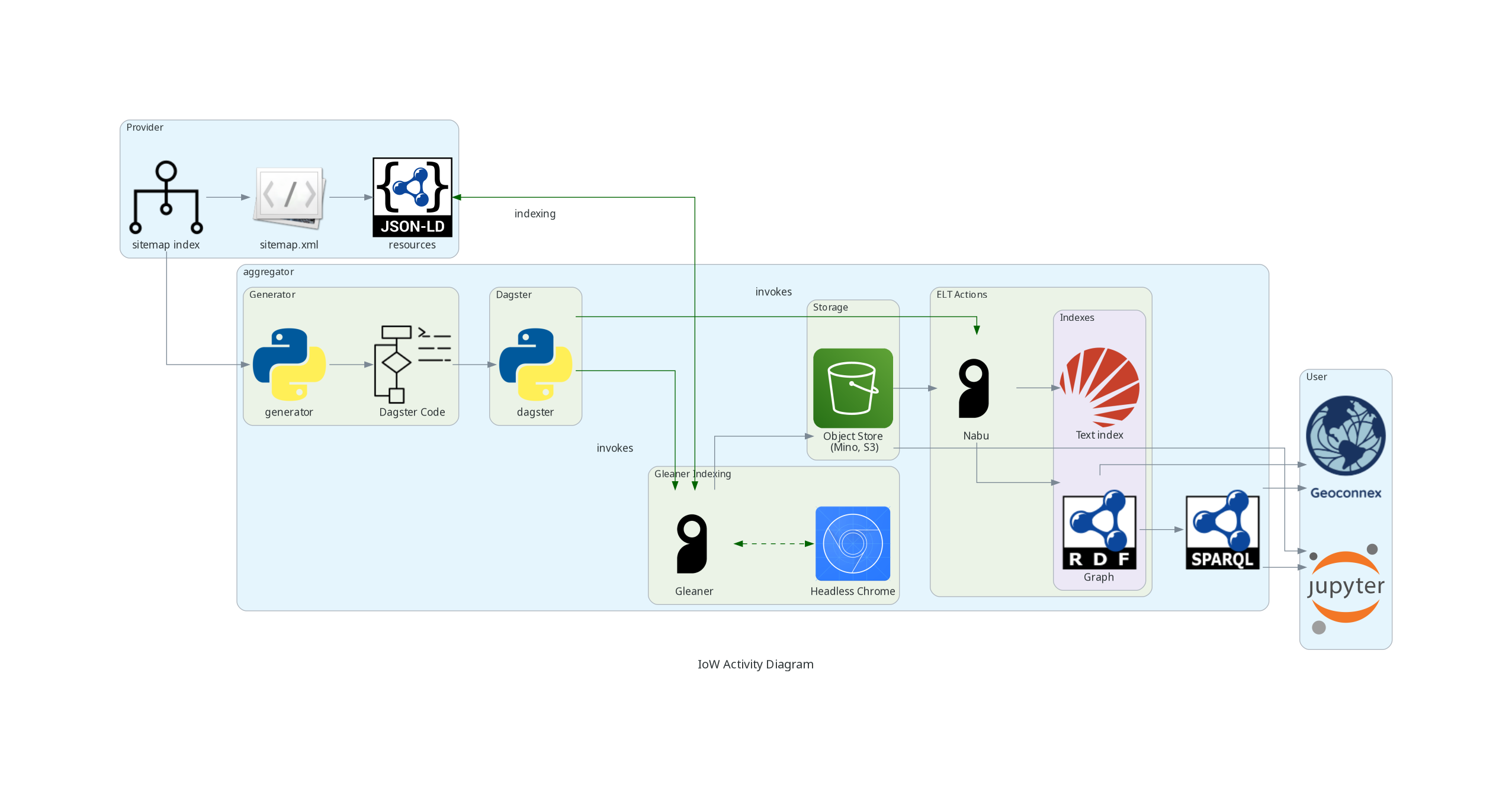
Example activity diagram for one user (Internet of Water)
FAIR Principles
Recall the FAIR principles which are noted at many locations. For reference you can visit the Go-FAIR FAIR Principles page.
Findable
| Principles | Project |
|---|---|
| Resolvable URIs that resolve to metadata records | Web architecture based indexing Proper @id use in JSON-LD |
| Use PIDs and Controlled Vocabularies | Harvested data graphs (JSON-LD) to form a KG. Keywords and other elements leverage PIDs and resolvable terms |
| Validation here though indexing and inspection | Data graphs can be framed and used for spatial, text or semantic indexes |
Accessible
| Principles | Project |
|---|---|
| Distribution URLs | Implemented with schema:distribution or related |
| Access control details | Implemented with schema:conditionOfAccess or related |
| Validation | We can implement validation of these elements with SHACL. This allows us to build reports and continuous integration style approaches |
Interoperable
| Principles | Project |
|---|---|
| Open formats | JSON-LD |
| Open vocabularies | schema.org, DCAT, GeoSPARQL, PROV |
| Define associated data models | Connect established data models and or associated tooling (GeoCODES resources registry) |
Reusable
| Principles | Project |
|---|---|
| License | schema:license or related (again, here we can leverage SHACL validation) |
| Community standards | Ocean InfoHub, POLDER, CCADI, GeoCODEs, Internet of Water |
Users
The users of GleanerIO can really be seen as examples of things like Go FAIR Implementation Networks or related.
Examples of such groups using this tooling follow.
Users of Gleaner
The following are some communities using or exploring the use of Gleaner.

https://geocodes.earthcube.org/
GeoCODES is an NSF Earthcube program effort to better enable cross-domain discovery of and access to geoscience data and research tools. GeoCODES is made up of three components respectively.
 Ocean InfoHub
Ocean InfoHub
The Ocean InfoHub (OIH) Project aims to improve access to global oceans information, data and knowledge products for management and sustainable development.The OIH will link and anchor a network of regional and thematic nodes that will improve online access to and synthesis of existing global, regional and national data, information and knowledge resources, including existing clearinghouse mechanisms. The project will not be establishing a new database, but will be supporting discovery and interoperability of existing information systems.The OIH Project is a three-year project funded by the Government of Flanders, Kingdom of Belgium, and implemented by the IODE Project Office of the IOC/UNESCO.
Polder: Polar Data Discovery Enhancement Research
Federated metadata search for the polar regions will dramatically simplify data discovery for polar scientists. Instead of searching dozens of metadata catalogues separately, a user can come to a single search page.
This is a rapidly moving field and POLDER is working to find the best path forward for our community. POLDER is a collaboration between the Southern Ocean Observing System, Arctic Data Committee, and Standing Committee on Antarctic Data Management.
 Canadian Consortium for Arctic Data Interoperability
Canadian Consortium for Arctic Data Interoperability
The Canadian Consortium for Arctic Data Interoperability (CCADI) is an initiative to develop an integrated Canadian arctic data management system that will facilitate information discovery, establish sharing standards, enable interoperability among existing data infrastructures, and that will be co-designed with, and accessible to, a broad user base. Key to the CCADI vision are: standards and mechanisms for metadata, data and semantic interoperability; a distributed data exchange platform; streamlined data services with common entry, access, search, match, analysis, visualization and output tools; an intellectual property and sensitive data service; and data stewardship capacity.
 Internet of Water
Internet of Water
Geoconnex rests on widespread adoption of metadata best practices, automatically harvesting metadata and indexing data to real-world hydrologic features (e.g. lakes, reservoirs, wells, streams, water distribution systems, monitoring locations). The resulting water-specific search index will be browsable from a common water metadata catalog for the IoW network in both a human and machine-readable format.